kubernetes etcd란
etcd란?
etcd는 Key-Value 형태의 데이터를 저장하는 분산 스토리지이다. kubernetes의 구성 데이터, 상태 데이터 및 메타데이터를 관리한다.
etcd architecture
etcd는 이레 그림과 같은 레이어로 구성된다.
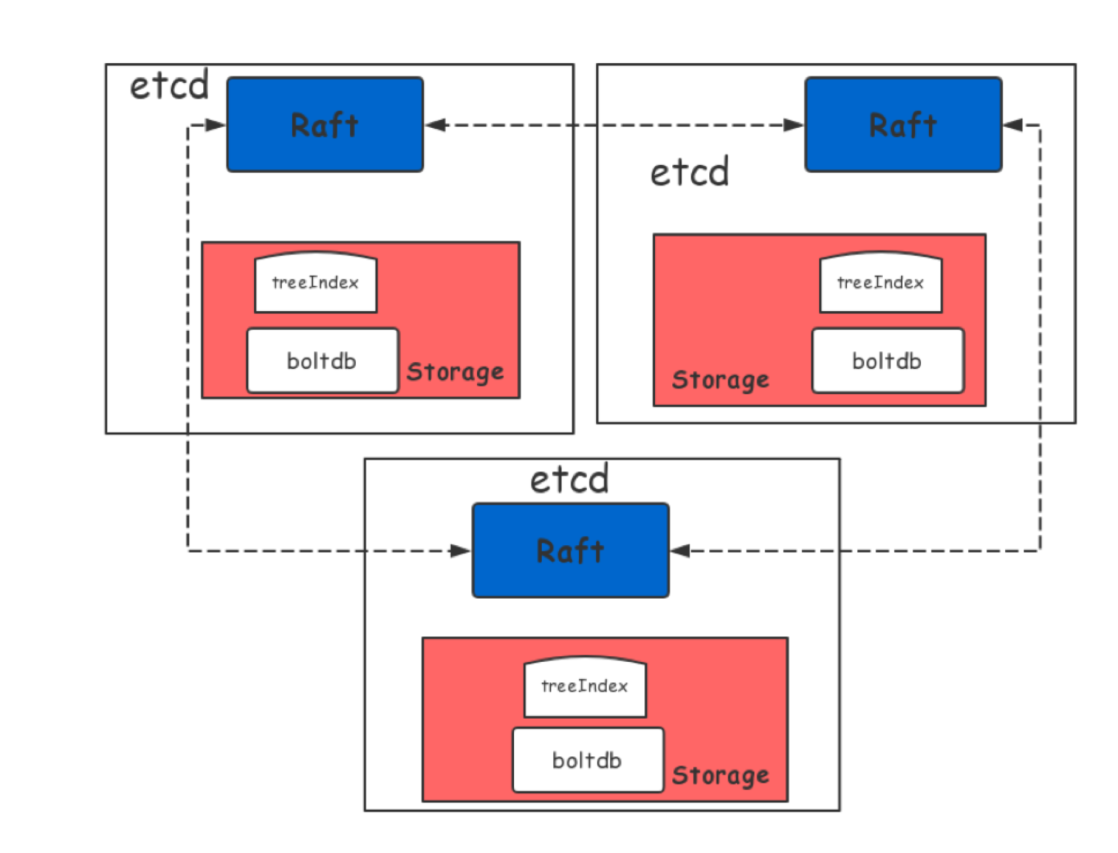
요소별 주요 역할은 다음과 같다.
| 항목 | Raft | TreeIndex | BoltDB |
|---|---|---|---|
| 목적 | 분산 합의 | 빠른 조회를 위한 메모리 인덱스 | 데이터 영속성을 위한 디스크 저장소 |
| 데이터 종류 | 로그 엔트리 | Key의 revision 히스토리 및 index | key, value, metadata |
| 저장 위치 | 메모리 + WAL | 메모리 (in-memory) | 디스크 (persistent storage) |
| 데이터 구조 | replicated log | B-tree 기반 index 구조 | B+tree 기반 embedded DB |
| 장애 대응 | leader election | 재시작 시 재구성 | source of truth |
| 클라이언트가 데이터를 조회할 때 거치는 경로 | 간접적 | 직접 사용 | 직접 사용 |
| 클라이언트가 데이터를 저장할 때 거치는 경로 | 반드시 통과 | 업데이트 발생 | 실제 commit |
etcd data 저장 흐름
- Write 요청 발생
- WAL에 먼저 기록 (Raft log 내구성 확보)
- WAL 은 Write-ahead logging 의 약자이다. 트랜잭션이 일어나기 전에 로그를 미리 기록하여 트랜잭션
undo,redo를 할 수 있도록 한다. - 실제 디스크에 저장된다.
- WAL 은 Write-ahead logging 의 약자이다. 트랜잭션이 일어나기 전에 로그를 미리 기록하여 트랜잭션
- BoltDB에 실제 데이터 저장
- TreeIndex에 revision 기반 index 업데이트
- 이후 Read 요청 시 TreeIndex를 통해 빠르게 key 위치 탐색
- 필요한 경우 BoltDB에서 실제 value 조회
즉, 다음과 같은 흐름을 가진다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
Client Write Request
│
▼
Raft 합의 프로세스
(메모리에서 처리)
│
▼
WAL에 Raft log 기록
(Raft log의 물리적 저장소)
│
▼
BoltDB
(실제 KV 데이터 저장)
│
▼
TreeIndex update
(revision 인덱스)
etcd의 데이터 모델 (BoltDB)
BoltDB는 Go 언어로 작성된 임베디드 ACID 키/값 데이터베이스이다.
- 쓰기 작업은 하나만 허용하고 읽기 작업은 여러 개 허용하는 섀도우 페이징 기능을 같춘 MVCC(다중 모드 제어)를 지원한다.
- 모든 트랜잭션은 직렬화 가능한 격리 환경에서 실행된다.
key-value쌍을 B+ Tree 데이터 저장소에 저장한다.
ETCD 특징
1. Revision (리비전)
etcd는 하나의 key에 대응되는 value를 하나만 저장하는 것이 아니라, 클러스터 생성 이후 key의 모든 변경사항을 기록한다.
- 각 변경사항은 revision 번호로 추적
- 과거 시점의 데이터 조회 가능
- 오래된 revision 데이터를 삭제하여 저장 공간을 확보 (Compaction)
- etcd 설정으로 시간 설정도 가능하다. (default: false)
2. RSM (Replicated State Machine)
분산된 환경에서 etcd가 동작할 경우, 여러 Server에서 CRUD가 발생하게 된다. etcd가 정상적으로 동작하기 위해서는 다른 Server들에서 이벤트가 발생하더라도 모든 Server의 etcd들이 동일한 데이터를 저장하고 있는것이 보장되어야 한다.
이렇게 똑같은 데이터를 여러 서버에 계속해서 복제하는 방식을 RSM (Replicated state machine)이라고 하며, RSM에 어떤 데이터를 복사할지를 결정하는 알고리즘을 Consensus Algorithm이라고 한다.
Raft Algorithm은 Consensus Algorithm의 한 종류로 서로 다른 Server들이 모종의 방법으로 합의를 통해 상태를 공유하는 알고리즘이다.
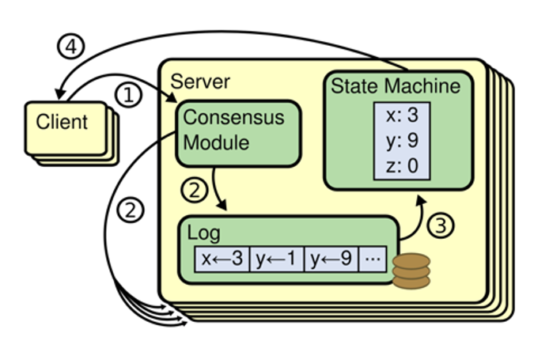
RSM의 특징
- Command가 들어있는 log 단위로 데이터 처리
- 데이터 write = log append
- 받은 log를 순서대로 처리
1. Log 기반 처리
etcd는 command가 들어있는 log 단위로 데이터를 처리한다.
- 데이터 write를
log append라고 부른다. - 받은 log를 순서대로 처리한다.
- Log entry는 메모리에 보관 후 주기적으로
snapshot을 생성한다.- default: 10만 개의 log entry마다 snapshot 생성
2. Consensus (합의)
Robust한 RSM을 만들기 위해서는 데이터 복제 과정에서 발생할 수 있는 문제를 해결하기 위해 컨센서스(consensus) 확보가 핵심이다.
| 속성 | 설명 |
|---|---|
| Safety | 항상 올바른 결과를 리턴 |
| Available | 서버가 몇 대 다운되어도 항상 응답 |
| Independent from timing | 네트워크 지연 발생해도 로그 일관성 유지 |
| Reactivity | 모든 서버에 복제되지 않아도 조건 만족 시 빠르게 응답 |
etcd는 이를 위해 Raft 알고리즘을 사용한다.
Raft 알고리즘
Raft는 etcd가 consensus를 확보하기 위해 사용하는 합의 알고리즘이다.
etcd Raft 알고리즘의 주요 개념
1. Quorum (쿼럼)
의사결정에 필요한 최소한의 서버 수를 의미한다.
- 계산식:
(전체 서버 수 / 2) + 1 - 예: 3대 서버 → 쿼럼 2
- 예: 5대 서버 → 쿼럼 3
쿼럼 숫자만큼의 서버에 데이터 복제가 완료되면 작업 완료로 간주한다.
2. State (상태)
etcd 서버는 다음 3가지 상태 중 하나를 가진다.
- Leader: 클라이언트 요청 처리 및 로그 복제
- Follower: Leader의 로그를 복제하고 동기화
- Candidate: Leader 선출 과정의 임시 상태
3. Timer (타이머)
- Heartbeat interval: Leader가 Follower에게 주기적으로 heartbeat 전송
- Election timeout: 이 시간 동안 heartbeat를 받지 못하면 Leader가 없다고 간주
4. Safety Rule (안전 규칙)
| 구분 | Term | Last Log Index |
|---|---|---|
| 범위 | 클러스터 전체 시간 | 개별 서버의 데이터 양 |
| 증가 시점 | Leader 선출마다 | 로그 추가마다 |
| 목적 | 시간적 순서 보장 | 데이터 완전성 보장 |
etcd의 Leader Election (리더 선출)
초기 클러스터 구성
1
2
3
[Server 1] [Server 2] [Server 3]
Follower Follower Follower
Term: 0 Term: 0 Term: 0
- 모든 서버가 Follower 상태로 시작
- Term(임기) 값을 0으로 설정
- Leader가 없으므로 heartbeat 없음
Election 과정
1
2
3
4
5
6
7
8
9
[Server 1] [Server 2] [Server 3]
Candidate → Follower Follower
Term: 1 Term: 0 Term: 0
↓
RequestVote RPC
↓
[Server 2, 3] → OK 응답
↓
[Server 1] → Leader 선출
- Election timeout 발생한 서버가 Candidate로 변경
- Term 값을 1 증가
- 다른 서버에게 RequestVote RPC 전송
- 쿼럼만큼 OK 응답 받으면 Leader 선출
- Leader는 주기적으로 heartbeat 전송
RequestVote 판단 기준
Follower는 다음을 비교하여 투표 결정
| 항목 | 조건 | 의미 |
|---|---|---|
| term | Candidate의 term ≥ 자신의 term | 더 최신 또는 같은 term |
| log index | Candidate의 log가 자신보다 최신이거나 같음 | 최소한 자신만큼은 최신 |
2. etcd의 Log Replication (로그 복제)
Write 요청 처리
1
2
3
4
5
6
7
8
9
10
Client → Leader: write(x=1)
↓
Leader: lastIndex 증가, log 기록
↓
Leader → Followers: AppendEntry RPC call
↓
Follower 1: log 기록 완료 → OK
Follower 2: 아직 기록 중...
↓
Leader: 쿼럼 달성 → Commit
- 사용자가 Leader에게 write 요청
- Leader가 자신의 log entry에 기록
- AppendEntry RPC로 Follower들에게 전파
- 쿼럼만큼 복제 완료되면 commit
- Commit = log entry → db(파일시스템)에 write
주요 개념
- lastIndex: 각 서버가 가진 마지막 log 번호
- nextIndex: Leader가 알고 있는 Follower가 받을 다음 log 번호
- Commit: log entry의 데이터를 db에 영구 저장
3. etcd의 Leader Down (리더 장애)
Leader 다운 시나리오
1
2
3
4
5
6
7
8
9
10
11
Leader 다운
↓
Follower들: election timeout
↓
Follower 2: Candidate로 변경
↓
Follower 1: RequestVote 거절 (더 최신 log 보유)
↓
Follower 1: election timeout → Candidate
↓
Follower 1: 새로운 Leader 선출
- Leader가 다운되면 heartbeat 중단
- Election timeout 발생한 Follower가 Candidate로 변경
- 더 최신 log를 가진 서버가 Leader로 선출
- 새 Leader는 나머지 서버와 log 동기화
구 Leader 복구
1
2
3
4
5
6
7
구 Leader 복구
↓
새 Leader로부터 heartbeat 수신
↓
자신의 term < 새 Leader의 term
↓
Follower로 변경, term 업데이트
- 낮은 term과 lastIndex를 가진 구 Leader는 자동으로 Follower로 전환
ETCD HA
Kubernetes control plane을 HA로 구성하는 경우, ETCD에 대한 HA도 필요하다. ETCD는 기본적으로 쿼럼 기반 Raft 알고리즘을 사용하므로, HA 구성에서 최소 3대 이상의 node가 필요하며, 홀수 대수를 추천한다.
예를 들어 다음과 같다.
| 클러스터 크기 | 쿼럼 | 허용 장애 노드 수 | 권장 사용 |
|---|---|---|---|
| 1개 | 1 | 0개 | 개발/테스트 |
| 3개 | 2 | 1개 | 소규모 프로덕션 |
| 5개 | 3 | 2개 | 대규모 프로덕션 |
| 7개 | 4 | 3개 | 대규모 프로덕션 |
왜 홀수? 과반수 합의를 위해 홀수가 효율적입니다. 4개와 5개 모두 1개 장애까지만 허용하므로, 5개가 더 경제적이다.
ETCD HA에는 2가지 방법이 있다.
1. Stacked etcd topology
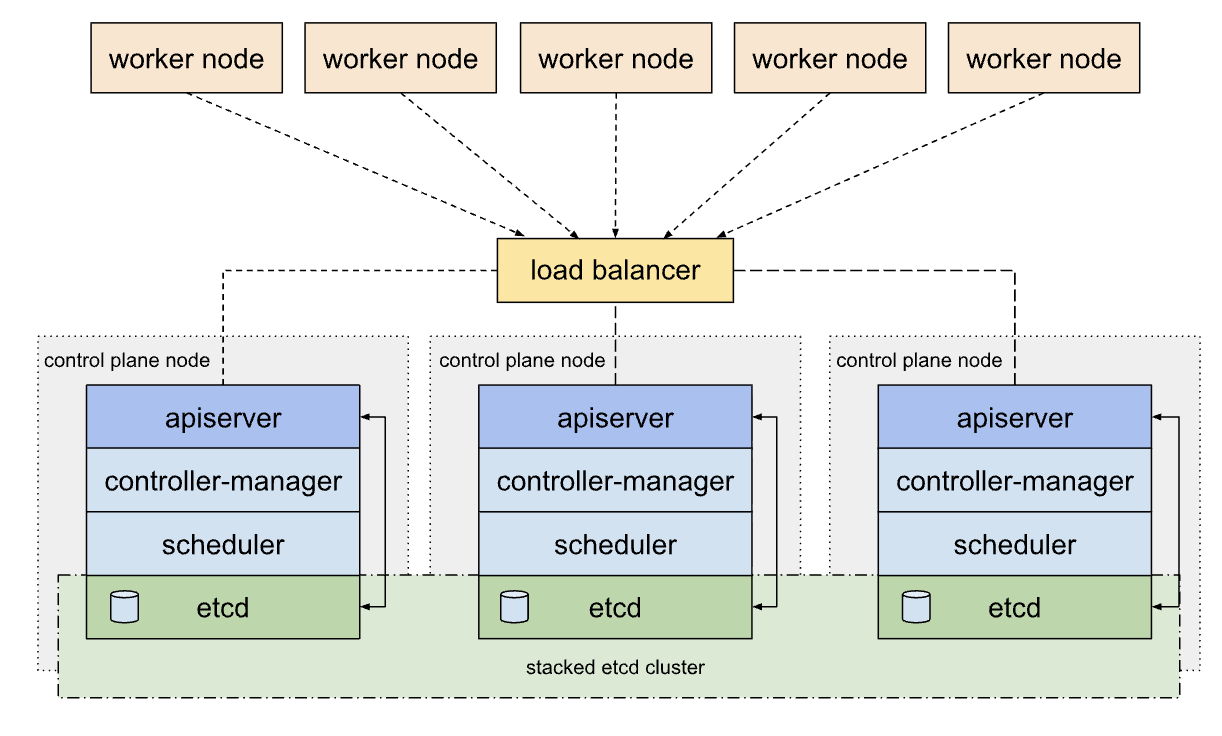
각 컨트롤 플레인 노드는 지역 etcd 맴버를 생성하고 이 etcd 맴버는 오직 해당 노드의 kube-apiserver와 통신한다. 즉, 컨트롤 플레인과 etcd 맴버가 같은 노드에 묶여 있다.
이 HA의 경우, control plane 장애에 etcd도 함께 영향을 받기 때문에, 2대 이하 nodes의 경우 장애 발생 시 etcd quorum을 상실하게 된다.
때문에 최소 3대 이상의 nodes가 필요하다.
2. External etcd topology
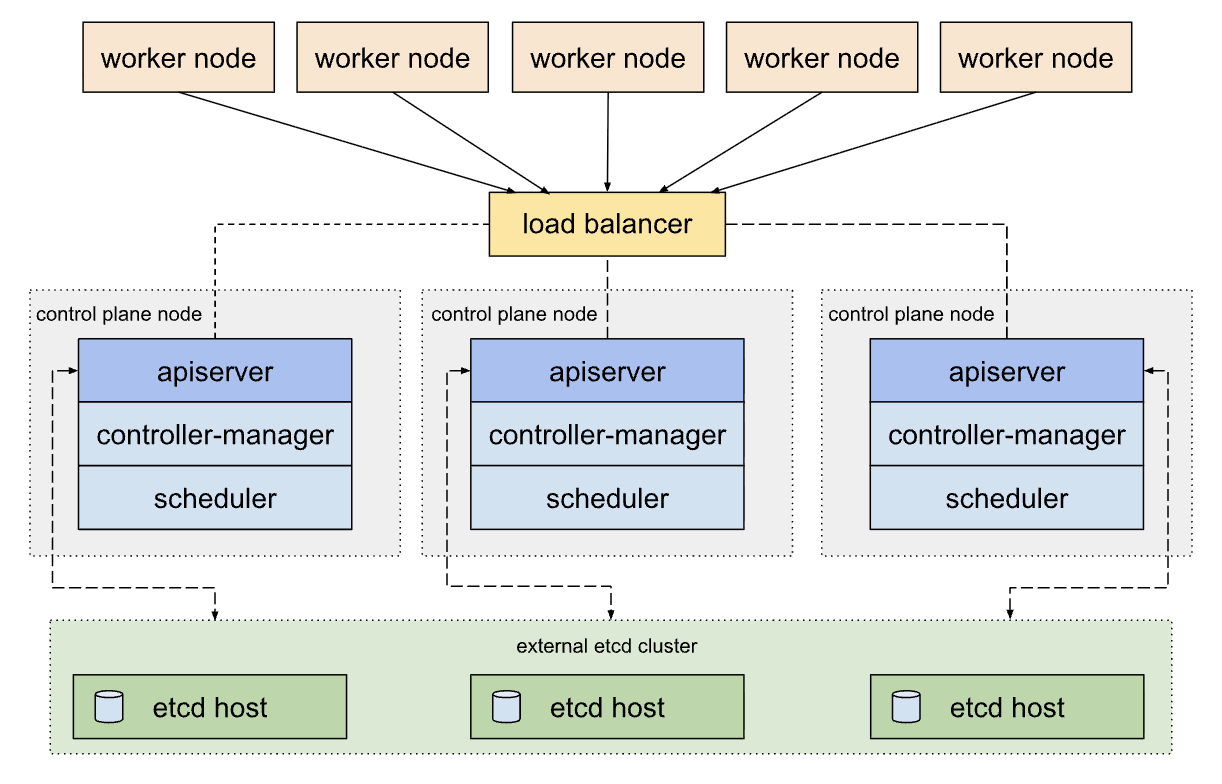
중첩된 etcd 토플로지와 유사하게, 외부 etcd 토플로지에 각 컨트롤 플레인 노드는 kube-apiserver, kube-scheduler, kube-controller-manager의 인스턴스를 운영한다.
이는 etcd를 control plane과 분리하기 때문에 control plane 장애에 etcd가 영향을 받지 않는다. 대신 etcd cluster를 구성하기 위해 Stacked etcd topolocy에 비해 호스트 개수가 2배나 필요하다. (최소 6대)
kubernetes에서의 etcd
Kubernetes 클러스터에서 etcd는 다음과 같은 특징으로 높은 신뢰성을 제공한다.
주요 특징
- 강력한 일관성(Strong Consistency): Raft 합의 알고리즘 사용
- 고가용성(High Availability): 클러스터 구성으로 단일 장애점 제거
- 분산 환경 지원: 여러 서버에 데이터 복제
- Watch 기능: 키 변경사항 실시간 감지
- Revision 관리: 모든 변경 이력 추적
ETCD의 주요 저장 데이터는 다음과 같다.
주요 저장 데이터
| 카테고리 | 리소스 | 설명 |
|---|---|---|
| 리소스 정의 | Pods | 실행 중인 컨테이너 정보 |
| Services | 서비스 엔드포인트 및 설정 | |
| Deployments | 배포 상태 및 스펙 | |
| ReplicaSets | 복제본 관리 정보 | |
| StatefulSets | 상태 유지 애플리케이션 정보 | |
| 설정 데이터 | ConfigMaps | 애플리케이션 설정 |
| Secrets | 민감한 정보 (암호화 저장) | |
| 클러스터 메타데이터 | Nodes | 노드 상태 및 리소스 정보 |
| Namespaces | 네임스페이스 정의 | |
| Events | 클러스터 이벤트 로그 | |
| 정책 및 권한 | RBAC | Role, RoleBinding, ClusterRole 등 |
| NetworkPolicies | 네트워크 정책 | |
| PodSecurityPolicies | Pod 보안 정책 |
etcd 데이터 확인 방법
- etcd Pod에 접속
1
kubectl exec -it etcd-devops-controlplane-01 -n kube-system -- sh
- etcdctl 명령어 실행 시 필요한 인증 정보 setting
1
2
3
4
export ETCDCTL_API=3
export ETCDCTL_CACERT=/etc/kubernetes/pki/etcd/ca.crt
export ETCDCTL_CERT=/etc/kubernetes/pki/etcd/server.crt
export ETCDCTL_KEY=/etc/kubernetes/pki/etcd/server.key
- 전체 디렉토리 조회
1
etcdctl get / --prefix --keys-only
- resource list 조회
1
2
3
4
5
6
7
8
# Pod 목록
etcdctl get /registry/pods --prefix --keys-only
# Deployment 목록
etcdctl get /registry/deployments --prefix --keys-only
# Service 목록
etcdctl get /registry/services --prefix --keys-only
- 특정 resource의 상세 정보 조회
1
2
# 특정 Pod 상세 정보 (JSON 형태)
etcdctl get /registry/pods/argocd/argocd-application-controller-0
- versioning 조회
1
2
3
4
5
6
7
8
9
10
11
# 최신 값 조회
etcdctl get /registry/pods/argocd/argocd-application-controller-0
# revision 12의 데이터 반환: "3"
# 특정 시점 조회
etcdctl get /registry/pods/argocd/argocd-application-controller-0 --rev=8
# revision 8의 데이터 반환: "2"
# 변경 이력 조회
etcdctl get /registry/pods/argocd/argocd-application-controller-0 --rev=5
# revision 5의 데이터 반환: "1"
API Server와 etcd의 상호작용
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
kubectl apply -f deployment.yaml
↓
API Server: 요청 검증
↓
API Server → etcd: write 요청
↓
etcd: Raft 합의 → commit
↓
API Server ← etcd: 성공 응답
↓
API Server → kubectl: 성공 응답
↓
Controller Manager: etcd watch로 변경 감지
↓
Controller Manager: 실제 리소스 생성
- kubectl이 API Server에 요청
- API Server가 etcd에 데이터 저장
- etcd가 Raft 알고리즘으로 합의 후 commit
- Controller Manager가 watch로 변경 감지
- 실제 리소스 생성/수정
핵심 요약
- 무엇: Key-Value 형태의 분산 스토리지
- 어떻게: RSM + Raft 알고리즘으로 consensus 확보
- 왜: 분산 시스템의 신뢰할 수 있는 단일 진실 공급원
- 어디서: Kubernetes, Cloud Foundry, CoreDNS 등